
03_深入跟踪plt和got表
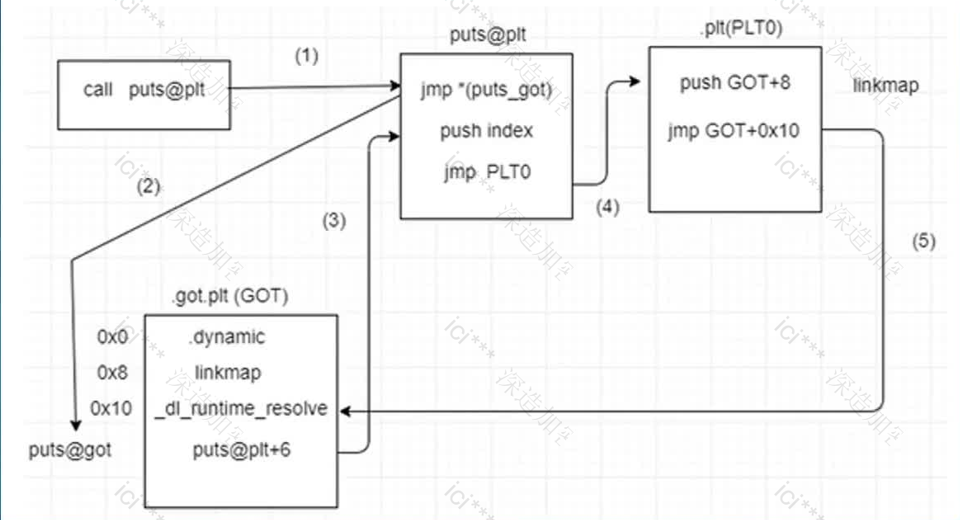
下面是对给出的流程图中 ELF 程序中函数调用过程(以 puts 为例)的详细分析。这反映了 ELF 动态链接中 PLT(Procedure Linkage Table)与 GOT(Global Offset Table)协作进行延迟绑定(lazy binding)的机制。当程序第一次调用一个动态库函数(例如 puts)时,会经过一系列跳转和解析步骤,最终将该函数的实际地址填入 GOT,使之后的调用直接跳转到最终函数入口点。
以下是图中所示流程的详细解析步骤(对应图中标注的序号):
call puts@plt: 源代码中当我们调用
puts("hello")这类函数时,编译后的代码并不会直接调用 puts 的真实地址。取而代之的是对puts@plt的调用(call 指令将控制权转移到 .plt 区域中的 puts 函数 stub)。这是因为在编译阶段还不知道动态链接库中 puts 的确切地址。*jmp putsgot(首次调用前 putsgot 中为 PLT0 的地址): 在 .plt 区域中针对 puts 的入口通常会先从 GOT 中取得函数的实际地址:
jmp *puts@got(%rip)
但在程序刚加载时,puts@got 这个位置并没有存储 puts 的实际函数地址,而是存放指向 .plt0 段的地址(即解析入口点)。因此,该跳转会转向 PLT0 stub,而非直接跳到 puts 函数体。
.got.plt (GOT 表项): GOT 中储存了动态链接中的信息,如:
0x0:.dynamic段指针0x8: 指向 link_map 结构的指针,用于运行时链接器了解当前进程加载的动态库信息。0x10: 存放对应函数(puts)的重定位信息以及将来要填入的实际函数入口地址。初始时,
puts@got的值会指向.plt0的一段通用解析代码。此处的目的是在函数第一次调用时,对函数进行真正的符号解析和重定位。
.plt0(通用延迟解析入口代码): 当代码跳转到 PLT0 时,会执行类似如下指令序列:
pushq GOT+8 ; 推入 link_map 指针(用于动态解析器,描述已加载库)
jmp *GOT+0x10 ; 跳转至 _dl_runtime_resolve
此时,控制权交给运行时链接器(通常是 ld-linux.so 或者类似的动态加载器内部函数 _dl_runtime_resolve)。这个函数知道如何根据被调用的符号(此处为 puts)在已加载的共享对象中找到正确的地址。
dlruntimeresolve 动态解析:
_dl_runtime_resolve会读取压入栈中的信息(如被调用函数索引、对应的 linkmap 信息),然后在已加载的共享库中找到该符号(例如在 libc 中查找 puts),取得 puts 的实际内存地址。找到地址后,动态解析器将该函数的真实地址写回到
puts@got的条目中。这样下次调用同一函数时,jmp *puts@got将不再跳转到解析入口,而是会直接跳转到已解析好的实际 puts 函数地址。
总结:
第一次调用: 程序调用
puts@plt→jmp *puts@got(此时指向 PLT0) → PLT0 通过_dl_runtime_resolve查找符号地址 → 将真实的 puts 地址回填到puts@got。后续调用: 下一次再执行到
puts@plt时,jmp *puts@got已经是 puts 的真实函数地址,不需要再进行解析,直接跳到真实的 puts 函数执行。
整个过程即实现了“延迟绑定”:只有在函数第一次被调用时才进行符号解析和 GOT 表项回填,从而减少程序启动时的初始解析开销。
知道函数的libc之后,我们可以libcsearcher去查询,或者在线查询